Skip List
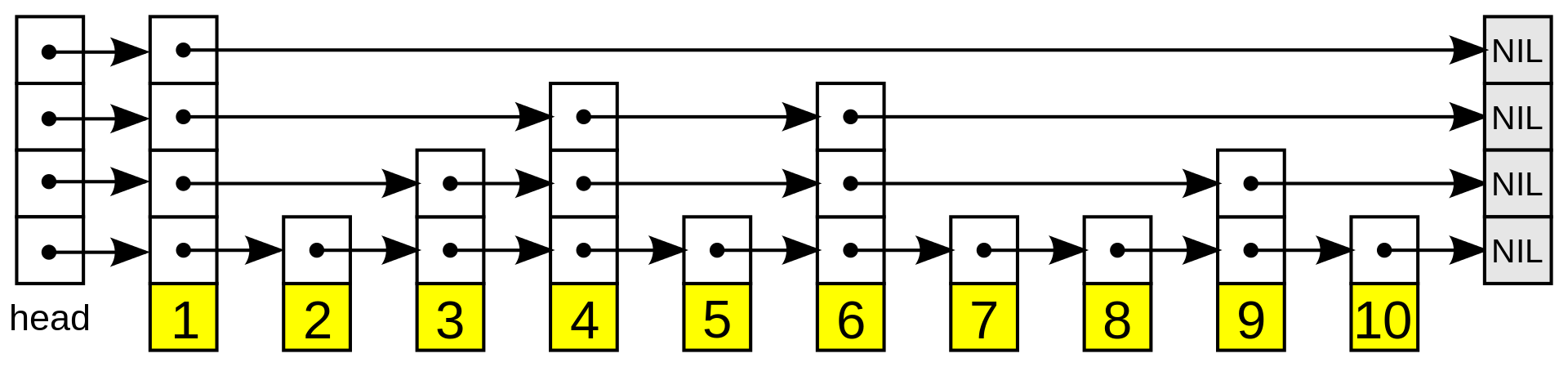
Skip List is a data structure, invented to solve the problem of organizing data for quick searching purposes. Despite its simple design, it provides relatively good performance, on average $O\lparen log~n\rparen$, for both searching, insertion and deletion operations. So how does it work?
The Searching Problem
Searching is one of the oldest and most ubiquitous problems in the world of computer science. Many solutions have been created to solve this, and each solution has its own strengths and weaknesses.
The first solution is quite simple, which is to use an Array containing data, arrange them in ascending or descending order, then use a Binary Searching algorithm to quickly find the desired element in this array. The solution gives good search time complexity, on average $O\lparen log~n\rparen$. However, the time complexity required to insert or delete elements in the array is not very good, on average $O\lparen n\rparen$, because both operations require shifting elements in the array one after another.
There is a data structure to hold sorted data and give $O\lparen 1\rparen$ insertion and deletion time complexity, which is Linked List. However, because Linked List does not support random access, to find a position in the middle of the list, we must search from the beginning of the list, so the time to find the position to insert is $O\lparen n\rparen$. Using a Linked List eliminates the ability to quickly search, which is the core requirement of the solution.
Self-balancing Binary Search Tree family data structures solve the search problem very well, on average $O\lparen log~n\rparen$, and at the same time give good insertion and deletion time complexity of $O\lparen log~n\rparen$. However, they are complex organized data structures as those trees are not simple to balance, hence not so easy to implement.
And that's where Skip List shines.
The Structure of Skip List
Inside the core Skip List utilizes Linked List to store data. Its improvement lies in the addition of layers. Each layer is a Linked List, however, the higher the layers, the smaller the number of elements. The reduction in the number of elements by layer is expected to decrease exponentially:
L2: | - - - - - - - 4 - - - - - - - - - - - null
L1: | - - - 2 - - - 4 - - - 6 - - - 8 - - - null
L0: | - 1 - 2 - 3 - 4 - 5 - 6 - 7 - 8 - 9 - null
In the example above, we have a Skip List with 3 layers: $L_0$, $L_1$, $L_2$. $L_0$ is the bottom layer, a Linked List with all elements sorted. Layer $L_1$ is located above $L_0$, consisting of only 2, 4, 6, 8, the number of elements is reduced to half compared to $L_0$. Layer $L_2$ is above $L_1$, there is only 1 element left: 4.
At each layer there are two additional special elements: a sentinel element located at the beginning of the list, represented by the character |, and a null element located at the end of the list, represented by null. They mark the beginning and the end of the list.
Searching in a Skip List
So how does Skip List help in searching an element? The answer is that we always start searching from the highest layer of the Skip List, where there are the fewest elements, then gradually go down to lower layers if we still can't find it. With each step down to the next layer, we only start searching from the element corresponding to the element we just traversed in the previous layer (called checkpoint) and ignore all elements before that checkpoint. The search ends as soon as the desired element is found in any layer.
To illustrate this concept, let's find element 6:
- Start at $L_2$, browse through: 4, null. Because 6 > 4 and we reached the end of current layer, go down to $L_1$ with 4 as checkpoint.
- At $L_1$, skip 4 and all elements before, browse through: 6. Because 6 = 6, we found it.
L2: | ============= 4 - - - - - - - - - - - null
L1: | - - - 2 - - - 4 =====[6]- - - 8 - - - null
L0: | - 1 - 2 - 3 - 4 - 5 - 6 - 7 - 8 - 9 - null
Now, let's find element 3:
- Start at $L_2$, browse through: 4. Because 3 < 4, we know that we can't find 3 in this layer, go down to $L_1$ and search from the beginning.
- At $L_1$, browse through: 2, 4. Because 3 > 2 and 3 < 4, we know that we can't find 3 in this layer, go down to $L_0$ with checkpoint 2.
- At $L_0$, skip 2 and all elements before, browse through: 3. Because 3 = 3, we found it.
L2: | - - - - - - - 4 - - - - - - - - - - - null
L1: | ===== 2 - - - 4 - - - 6 - - - 8 - - - null
L0: | - 1 - 2 =[3]- 4 - 5 - 6 - 7 - 8 - 9 - null
Building a Skip List
Skip List is built from the lowest layer $L_0$ which is a Linked List containing all sorted elements. Then, gradually build up the layers above $L_1$, $L_2$, $L_3$. To build these layers, the way is to go through all elements of the layer below, at each element, flipping a coin to decide whether or not that element will be picked up to the current layer.
Let's illustrate the concept by builing this Skip List:
L2: | - - - - - - - 4 - - - - - - - - - - - null
L1: | - - - 2 - - - 4 - - - 6 - - - 8 - - - null
L0: | - 1 - 2 - 3 - 4 - 5 - 6 - 7 - 8 - 9 - null
They recommend the number of layers a Skip List with $n$ elements should have is about $log_2~n$. This Skip List has 9 elements, $log_2~9~\approx~3$, so we should build 3 layers.
Start by building $L_0$, we sort all elements and build a Linked List. This should be straightforward:
L0: | - 1 - 2 - 3 - 4 - 5 - 6 - 7 - 8 - 9 - null
Now, to build $L_1$, we loop through all elements in $L_0$. At each element, we flip a coin to decide if that element should be promoted to $L_1$. Let say if it's Head (H), we promote that element, if it's Tail (T), we leave it.
L1: | - - - 2 - - - 4 - - - 6 - - - 8 - - - null
T H T H T H T H T
L0: | - 1 - 2 - 3 - 4 - 5 - 6 - 7 - 8 - 9 - null
To build $L_2$, we loop through all elements in $L_1$ and also do the coin flips:
L2: | - - - - - - - 4 - - - - - - - - - - - null
T H T T
L1: | - - - 2 - - - 4 - - - 6 - - - 8 - - - null
It's easy to see that the content of the Skip List depends on the result of the sequence of coin flips. And because the sequence of coin flip results depends on random probability, people call Skip List a probabilistic data structure. Skip List content after each build is not exactly the same but will be different depending on the probability.
Insertion
To insert new element into the Skip List, we find the appropriate position in the bottom layer, insert the element in that position, and promote it through upper layers using coin flips. Consider adding a new layer if the number of elements has grown beyond the limit, in this example, when $log_2~n~\approx~4$.
Let's insert 6 to this Skip List:
L2: | - - - - - - - 4 - - - - - - - - - null
L1: | - - - 2 - - - 4 - - - 7 - - - - - null
L0: | - 1 - 2 - 3 - 4 - 5 - 7 - 8 - 9 - null
No need to add a new layer cause after the insertion, number of elements is 9, which hasn't reached the limit.
Find the position in $L_0$, using searching procedure described above. Time complexity should be $O\lparen log~n\rparen$ in average. The position should be between 5 and 7:
L2: | ============= 4 - - - - - - - - - - - null
L1: | - - - 2 - - - 4 - - - - - 7 - - - - - null
L0: | - 1 - 2 - 3 - 4 = 5 -[*]- 7 - 8 - 9 - null
At this step we should record the search path we've gone through until reaching that position. Search path is an array of every checkpoints at every layers we touched. In this example, the search path through $L_2$, $L_1$, $L_0$ should be [4, 4, 5]. Search path is consulted later to know which element will be the predecessor of new element at each layer. This help to easily promote the new element.
Next, insert 6 to that position. This is just a simple Linked List insertion, time complexity of the operation should be $O\lparen 1\rparen$:
L2: | - - - - - - - 4 - - - - - - - - - - - null
L1: | - - - 2 - - - 4 - - - - - 7 - - - - - null
L0: | - 1 - 2 - 3 - 4 - 5 -[6]- 7 - 8 - 9 - null
By consulting the search path [4, 4, 5], we know that:
- The predecessor of 6 at $L_0$ is 5.
- The predecessor of 6 at $L_1$ is 4.
- The predecessor of 6 at $L_2$ is 4.
Now, promote that new element through upper layers using coin flips, see how far the element could go up:
L2: | - - - - - - - 4 - - - - - - - - - - - null
T
L1: | - - - 2 - - - 4 - - - 6 - 7 - - - - - null
H
L0: | - 1 - 2 - 3 - 4 - 5 - 6 - 7 - 8 - 9 - null
The promotion stops at $L_1$, we have this Skip List as final result:
L2: | - - - - - - - 4 - - - - - - - - - - - null
L1: | - - - 2 - - - 4 - - - 6 - 7 - - - - - null
L0: | - 1 - 2 - 3 - 4 - 5 - 6 - 7 - 8 - 9 - null
Deletion
To remove an element from the Skip List, we find that element and remove it from every layers it appears. Consider removing top layer if it becomes empty. Time complexity should be $O\lparen log~n\rparen$ in average.
Memory consumption
This data structure consumes about twice as much memory as a Linked List with the same number of elements. That's the price to pay for its speed.